<{配资之家}>大数据产品系列开篇:聚焦宏观架构,解析大数据及多源异构特点

这是大数据产品系列文章的第一篇,我写这个系列的原因在于:
1、系统掌握大数据体系架构。
2、了解技术原理,熟悉数据全流程。
3、用理论去解释、指导工作,形成个人方法论。
4、防止不懂原理乱提需求,或提不出需求。
5、希望找到有共同职业路径的产品经理,交流经验。
本文目标:关注大数据宏观架构,细节不讲。
什么是大数据
说到大数据,首先会想到数据量非常大,除了常见的结构化数据,还包含很多非结构化数据,例如视频、音频、图片、文本、文件等。从整体视角来看,海量数据价值密度低,存在很多“垃圾”数据,这是因为数据来源具有多源异构的特点。所谓多源是数据可以来自各种系统,以阿里举例,数据源可以来自淘宝、天猫、支付宝、高德等等系统,异构是这些数据结构、存储方式各不相同。
汇聚海量数据后必须快速处理来满足业务,PB级甚至EB级数据量对处理能力提出了很高的要求。如果不能对海量数据进行有效、结构地分类、存储、处理、治理、挖掘,那就是一场数据灾难。
因此大数据在一定时间范围内没法用常规的工具进行存储、处理,它需要区别于传统数据处理的方法进行组织,实现价值密度提升,完成从数据到数据资产的转化。
怎么完成数据资产转化
实现数据资产转化需要建设一套高效的数据体系和模型。其最大的好处就是让数据易用避免重复建设和数据不一致,保证数据质量、规范、性能。实现这一目标业内通用的解决方案都是基于Hadoop生态体系进行改造。
Hadoop是目前应用最为广泛的分布式大数据处理框架,其具备可靠、高效、可伸缩等特点。可能这句话比较难理解,大白话就是,有几千上万台服务器,让每台各司其职,当硬盘的就稳定存好数据,处理数据的就高效保质保量的完成任务,当管理者的服务器就监控好各个节点,要稳定,一台崩了安排另一台顶上,N台服务器稳定的协同、齐心协力,共克时艰。
大数据体系架构
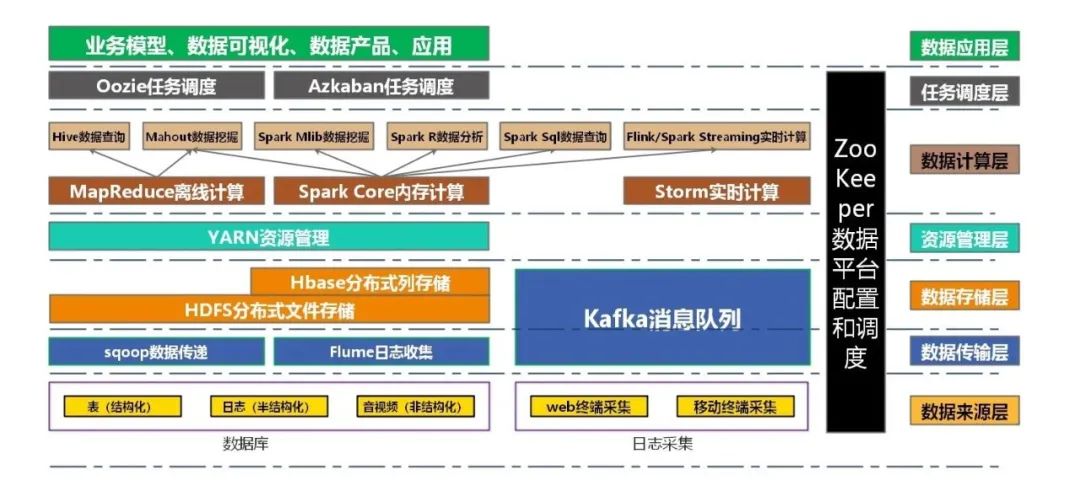
基于Hadoop大数据体系
各家企业选择的大数据体系架构大同小异,分层方法也各不相同,比如有的公司把数据来源层,数据传输层合并后定义为数据采集层。把数据传输、存储、资源管理层定义为数据计算层等。分层方法并不重要,了解其中原理就好。
理解架构
1.数据来源层

例如,腾讯业务板块涵盖社交、娱乐、商业等,各种业务系统标准不一,数据不同。但是数据来源基本涵盖两大体系,数据库和日志采集。数据库的数据一段时间内相对稳定,狭义上可定义为总量数据,它的数据分为结构化、半结构化、非结构化;
日志采集数据一般是实时增加的,可定义为增量数据,通常为结构化数据。日志采集中又分为pc端(web)采集和移动端(app)采集。pc端又有分浏览日志和交互行为采集,app端分页面事件和控件点击的采集。
2.数据传输层

Sqoop,是结构化数据/数据迁入迁出工具,主要用于传统数据库往Hadoop里导入数据。
Flume,是分布式日志采集工具,适合复杂环境的海量日志收集。它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,Flume还可以对日志数据进行简单处理,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标的能力。
Flume以Agent为最小的独立运行单位,单个Agent由Source、Sink和Channel三大组件构成。
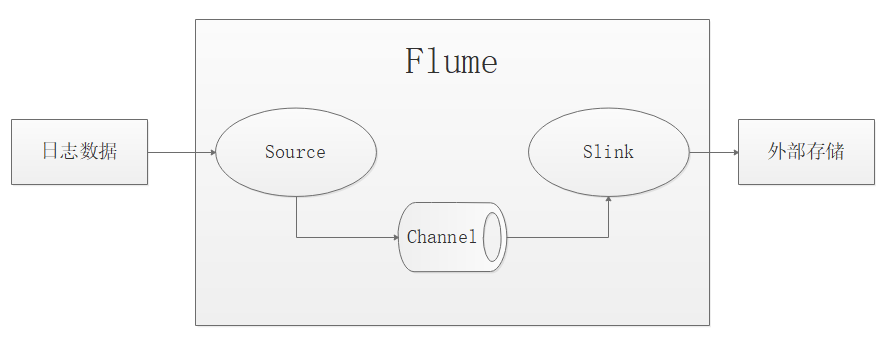
Source:从数据库收集数据,并传递给Channel。
Channel:缓存区,将Source传输的数据暂时存放。
Sink:从Channel收集数据,并写入到指定地址。
Kafka,是一种高吞吐量的分布式发布订阅消息系统,是消息中间件的一种。它可以处理消费者规模的网站中的所有动作流数据。
先来理解什么是消息中间件,比如网友(消费者)每天只能吃1个明星(生产者)的瓜(消息),假如网友吃瓜吃撑了(宕机),明星还在爆料大瓜,网友吃不下了,瓜就丢失了。假如100个明星一次就爆料1000个瓜,这个网友肯定就撑的挂了,该网友希望慢慢吃,瓜农先把瓜放在瓜棚(中间件)存起来,想吃的时候再慢慢吃,这个瓜棚就是中间件。
Kafka重要组件,比如Producer、Consumer、Topic、Broker,Message简单说明一下。
Producer,生产者,明星-造瓜的
Consumer,消费者,网友-吃瓜的
Topic,类,给瓜分类的
Broker,池,瓜棚-存瓜的
Message,消息(Kafka内的数据),瓜
目前生产环境(实际运行的环境,相比还有开发环境和测试环境)中的最佳实践架构是Flume+Kafka+Spark Streaming。

3.数据存储层
HDFS,Hadoop分布式文件系统,负责数据的存储与管理。HDFS有着高容错性的特点,并且设计用来部署在低廉的硬件上,适合那些有着超大数据集的应用程序。可以理解为一堆价格不高的硬盘服务器并联,实现了超级NB的硬盘才能完成的任务。HDFS可以把一份超大号的文件切分以后放在不同的服务器进行管理。
如何管理切分后的大号文件?切完了存在哪?文件怎么切?
核心模块包括,NameNode,“主节点”,类似一个目录,管理文件存在哪的问题,有且仅有一个;DataNode,“从节点”,实际存数据的地方,前文说了为啥集群某台崩了,也不影响整体运行。因为一般的解决方案是一份文件存三个地方,所以一个崩了另一个顶上;Client,用来把大文件切分的保存的。
HBase,基于Hadoop的列式分布式NoSQL数据库,HBase是一个建立在HDFS之上,分布式NoSQL数据库 ,列式数据库,适合存储半结构化、非结构化数据 。
下边这个图表示传统关系型数据库的表,说明了厂子和业务之间的关系,用SQL查就行,很方便。但如果有一天沸腾厂开展了光刻机业务,那么就要增加新字段,改表结构是很麻烦的,而且还不能存图片数据,所以NoSQL可以解决这个问题。图随意画的,图个乐,如有雷同纯属巧合。
厂(PK)
视频业务
媒体业务
云服务
电商业务
福报厂
优酷
微博
阿里云
阿里巴巴
鹅厂
腾讯视频
腾讯网
腾讯云
拍拍
沸腾厂
NULL
心声社区
华为云
华为商城
NoSQL全名是Not Only SQL,不仅是SQL。NoSQL是一类数据库统称,并不单指某个,比如MongDB、HBase都是NoSQL。HDFS和HBase都是分布式的,HBase效率高的原因在于KV存储。Key的组成是rowkey+属性列+写入时间戳,Value就是value。
Key(rowkey+属性列+写入时间戳)
Value(value)
福报厂+视频业务+1月1日
优酷
福报厂+媒体业务+1月1日
微博
福报厂+云服务+1月1日
阿里云
沸腾厂+电商业务+1月2日
华为商城
沸腾厂+光刻机业务+1月3日
光刻机
……
……
可以看出,在不改表结构情况下就新增了光刻机。假如沸腾厂又新增飞机业务、航母业务,用NoSQL很轻易的就可进行数据修改。
数据存储层不只是HDFS和HBase这么简单,它是大数据中非常核心的内容,包括数仓建设和应用,关于数仓分层,通常为ODS层(操作数据层),DWD(明细数据层)、DWS(汇总数据层)、ADS(应用数据层),通过数仓不同层次加工从底往上实现数据资产向信息资产的转化,并且过程由元数据管理。元数据管理是定义数据的数据,这部分内容将在后续系列文章讲。
4.资源管理层

YARN,负责集群资源的统一管理和调度,提高集群的利用率,资源利用合理性性。该框架主要有ResourceManager,Applicationmatser,nodemanager。ResourceManager负责应用程序的资源分配,ApplicationMaster主要负责每个作业的任务调度,也就是说每一个作业对应一个ApplicationMaster。Nodemanager是接收Resourcemanager 和ApplicationMaster的命令来实现资源的分配执行体。
R接收到任务请求,会启动A负责作业的调度指挥,之后N负责干活。
4.数据计算层

计算层比较重要的包括离线计算和实时计算。
离线计算,MapReduce(分布式计算框架)是基于磁盘的分布式并行批处理计算框架,用于处理大数据量的计算。通常是离线数据计算,对数据运算时效要求不高。
具备高容错(任务失败,自动调度到其他节点重新执行)、高扩展(计算能力随着节点数增加,近似线性递增)、适用于大规模数据的离线批处理、降低了分布式编程的门槛。
MapReduce最终要的任务就是处理保存在HDFS里的文件,它的处理逻辑包含Map和Reduce。Map就是把各自服务器读的数据统计出来,例如服务器A(hello,123),服务器B(hello,456)....Reduce就是把它们汇总,MapReduce之所以慢是因为数据运算完后会写入磁盘,调用时再读,像Spark就运算完后在内存里进行下一步计算。所以MapReduce稳定性更好Spark速度更快。
实时计算,Flink(真正意义上的流处理)是一个基于内存的分布式并行处理框架,类似于Spark,但在部分设计思想有较大出入。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。Spark Streaming(伪流处理)允许程序能够通过短时批处理实现的伪流处理。
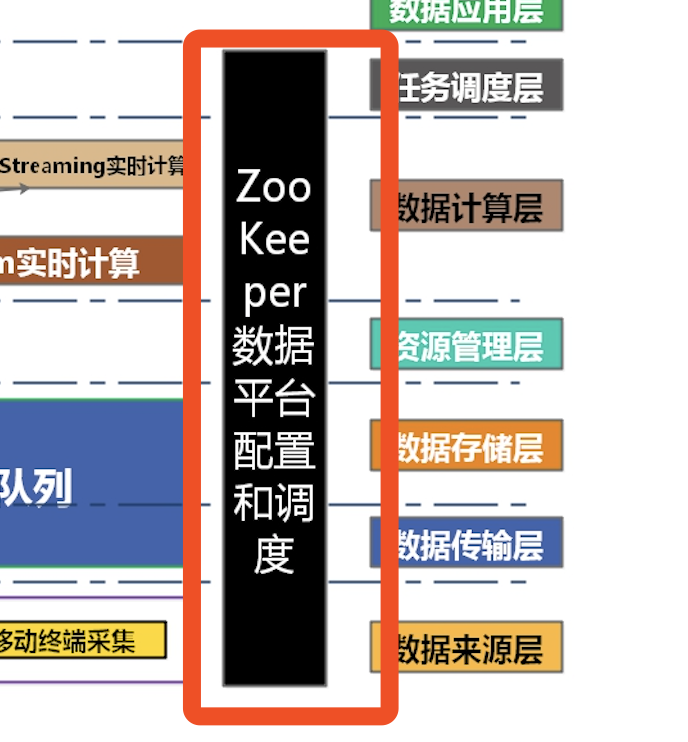
Zookeeper(分布式协作服务),解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
5.任务调度层

Oozie和Azkaban,这两都是任务调度的,两者在功能方面大致相同,而Azkaban可以直接操作shell语句。在安全性上可能Oozie会比较好。
6.数据应用层

数据整合计算好后,需给上层进行消费,开放给企业各部门使用,以数仓计算好的数据为源头,通过接口服务化方式对外提供数据服务。通过接口调用服务,形成数据产品,例如搜索、推荐、广告、数据分析、报表等等。
写在最后
以上内容粗略介绍了大数据体系框架,后续将从框架进行细分阐述。文章内容包括日志采集、数据同步、数仓建设、事实表维表设计、指标体系构建、元数据管理、数据质量管理等大模块进行阐述。文章内容基我无现有知识体系必然存在盲点,作为参考就好。
关注本公众号,第一时间获取干货信息
